上一篇提到的是抓圖片資料,這一篇就比較單純是抓網址及文字,今天示範的網站是一個日本的美食評比網站--tabelog。
今天我想要列印出商家英文名稱、日文名稱、菜的類別、評分、午餐價格、晚餐價格以及網址。
爬蟲第一步是要先找出它真正的網址,其實有一個簡單的測試,我先把畫面轉到第二頁,可以發現上方的網址列是有變動的,所以我大膽的推測我要的資訊可以直接從網址列找到,不需要另外找隱藏的網址。
打開原始碼後你會發現它不像是上一篇的json格式,是HTML網頁格式,如果忘記可以回去看我的Day15有提到~
好了要正式開始寫程式啦,今天會用到兩個函式庫分別是requests&BeautifulSoup,都是第三方的所以必須提前下載好。接著用get存取網址,將網頁的HTML程式碼取回來後,再來要用bs4傳入剛剛拿到的的HTML程式碼,並且指定一個解析型態,html.parser是Python內建的,如果你想要用速度最快的可以使用lxml套件,不過要記得import。
import requests
from bs4 import BeautifulSoup
url = "https://tabelog.com/tw/tokyo/rstLst/?SrtT=rt"
response = requests.get(url)
html = BeautifulSoup(response.text, "html.parser")
現在已經將程式碼變成HTML格式,它是一塊一塊的了,所以我就可以在每一區塊裡搜尋我想要的資料,方法有兩種:
由於我要抓的是每一間餐廳的好幾種資料,所以我需要先抓整個餐廳的程式碼下來再篩選我需要的,這邊可以用畫面中上方的方塊滑鼠直接點選想要的區塊,比較容易找到相對應的程式碼。可以注意到這個餐廳的HTML名字是li,代表它的型態是list,後面的class="list-rst"就可以當作篩選條件,如果你要用class="js-list-item"也可以!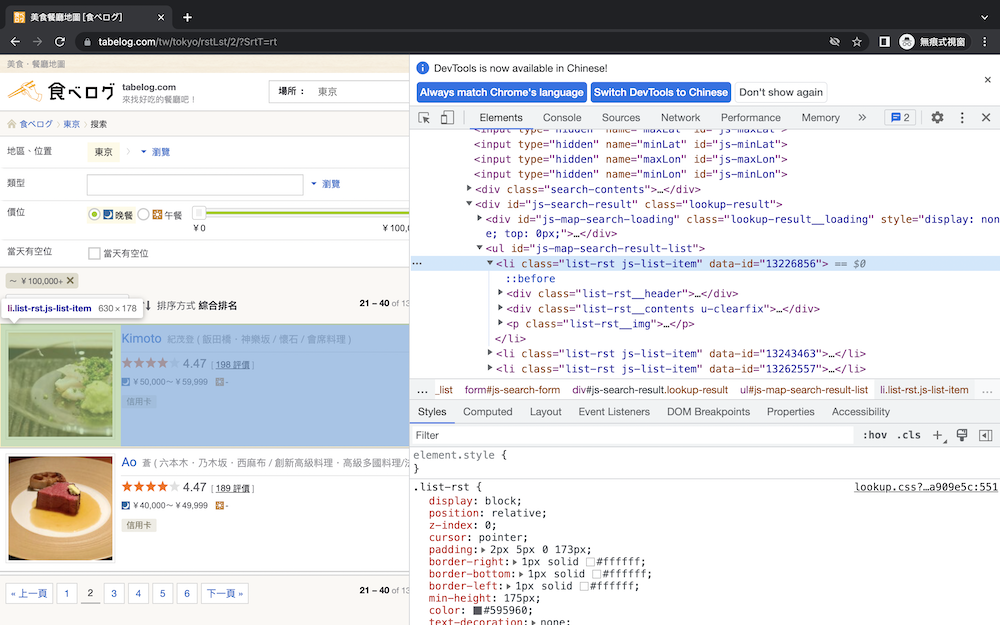
rest = html.find_all("li", {"class":"list-rst"}) # 找到整個餐廳的資料
接下來就是要跑過每一個餐聽,毫無疑問的就是使用迴圈。由於每一個區塊內只會有一個英文名稱、一個日文名稱...,所以這部份使用find就好了,就不使用find_all。裡面找每一個資料時都可以使用方塊滑鼠更快的找到相對應的程式碼,再根據它前面的HTML名字以及後面的篩選條件作微調,就可以輕鬆取得想要的資料。
for r in rest: # r: 一個li區塊
en = r.find("a", {"class":"list-rst__name-main"}) # 英文名稱
ja = r.find("small", {"class":"list-rst__name-ja"}) # 日文名稱
rtype = r.find("li", {"class":"list-rst__catg"}) # 菜的類別
rating = r.find("b", {"class":"c-rating__val"}) # 評分
price = r.find_all("span", {"class":"c-rating__val"}) # 價格
取得整個區塊後接著就要輸出。
for r in rest: # r: 一個li區塊
en = r.find("a", {"class":"list-rst__name-main"}) # 英文名稱
ja = r.find("small", {"class":"list-rst__name-ja"}) # 日文名稱
rtype = r.find("li", {"class":"list-rst__catg"}) # 菜的類別
rating = r.find("b", {"class":"c-rating__val"}) # 評分
price = r.find_all("span", {"class":"c-rating__val"}) # 價格
print(en.text)
print(ja.text)
print(rtype.text)
print(rating.text)
print("午餐:", price[0].text) # 午餐價格
print("晚餐:", price[1].text) # 晚餐價格
print(en["href"]) # 網址
print("-" * 30) # 分隔符號
import requests
from bs4 import BeautifulSoup
url = "https://tabelog.com/tw/tokyo/rstLst/?SrtT=rt"
response = requests.get(url)
html = BeautifulSoup(response.text, "html.parser")
# 區塊.find/find_all(區塊html名字, 篩選條件class/id)
rest = html.find_all("li", {"class":"list-rst"})
for r in rest: # r: 一個li區塊
en = r.find("a", {"class":"list-rst__name-main"}) # 英文名稱
ja = r.find("small", {"class":"list-rst__name-ja"}) # 日文名稱
rtype = r.find("li", {"class":"list-rst__catg"}) # 菜的類別
rating = r.find("b", {"class":"c-rating__val"}) # 評分
price = r.find_all("span", {"class":"c-rating__val"}) # 價格
print(en.text)
print(ja.text)
print(rtype.text)
print(rating.text)
print("午餐:", price[0].text) # 午餐價格
print("晚餐:", price[1].text) # 晚餐價格
print(en["href"]) # 網址
print("-" * 30) # 分隔符號


 iThome鐵人賽
iThome鐵人賽